
Vamos começar a ver o que é o MEAN Stack, quais seus componentes e características, entrando no mais importante deles: O Node.js. Veja o que é e como criar aplicações servidoras de altíssima performance com ele.
Sessão 1- C10K: Node.js, o Javascript no lado Servidor

O trabalho Workshop de Desenvolvimento com Stack MEAN de Cleuton Sampaio de Melo Jr está licenciado com uma Licença Creative Commons - Atribuição-CompartilhaIgual 4.0 Internacional.
Isso inclui: Textos, páginas, gráficos e código-fonte.

O que é o Stack MEAN?
Um “Stack” de desenvolvimento é um conjunto de ferramentas que, usadas em conjunto, possibilitam ou facilitam o desenvolvimento de aplicações. Um dos “Stacks” mais famosos é o LAMP (Linux + Apache + MySQL + PHP).
O Stack MEAN é composto pelas ferramentas:
- M: MongoDB (Licença: GNU AGPL v. 3.0) - Um poderoso banco de dados "no-SQL", que trabalha diretamente com objetos BSON / JSON, cuja performance com grande volume de dados o torna candidato ideal a uso em aplicações de "Big data";
- E: Express.js (Licença: MIT) - Um framework para criação de aplicações cliente-servidor, baseadas em Javascript e Node.js, que usem REST como API. Ele se define como um "web framework" para node.js, e faz um pouco do que o JSF e o JAX-WS fazem, no Java EE;
- A: Angular.js (Licença: MIT) - É um framework MVC para uso em páginas HTML, muito interessante. Feito pela Google, ele permite criar páginas HTML 5 dinâmicas, com a ajuda do “two-way data binding”;
- N: Node.js (Licença: Própria, tipo CopyLeft) - É uma aplicação que usa o engine Javascript V8, do Chrome, para criar aplicações servidoras, baseadas em "no blocking I/O", que respondem muito bem ao alto tráfego e grande volume de dados. Toda a programação da sua aplicação servidora é feita em Javascript;
Todas as ferramentas do Stack MEAN são livres, de acordo com os termos de suas licenças, e podem ser instaladas em qualquer plataforma, tanto para desenvolvimento como para produção.
Por que usar essas ferramentas?
O MongoDB é um banco de dados No-SQL, com todas as vantagens que isso proporciona, por exemplo:
- Escalabilidade elástica, ou seja, pode ser distribuído por vários nós e funcionar em ambientes de núvem. Ao contrário da maioria dos Bancos Relacionais (RDBMS), que apostaram muito na escalabilidade vertical (servidores mais potentes);
- Processamento de grandes volumes de dados (Big Data), através de sua escalabilidade elástica e de recursos como MapReduce, que permite transformar operações com grandes volumes de dados em operações paralelas, em nuvem;
- Simplicidade de modelo de dados, através do uso de Objetos, geralmente representados em JSON, permitem uma administração simplificada e mais próxima da programação da aplicação.
Por anos os desenvolvedores buscaram soluções para armazenar Objetos nos Bancos de Dados, ao invés de “tuplas”. Os bancos NoSQL realizaram esse sonho, pois podem lidar diretamente com Objetos, através de um modelo simplificado de relacionamento. Existem outros bancos NoSQL famosos, como o CouchDB, do grupo Apache, e alguns mais radicais, dedicados a outras funções, como o Redis.
O Node.js é uma plataforma que permite criar aplicações Servidoras utilizando Javascript. Em outras palavras, você não precisa mais de um Servidor Apache ou de um Container JAVA EE ™ para poder executar seu software servidor, pois pode utilizar a API do Node.js e criar tudo o que é necessário para disponibilizar serviços e páginas Web.
Mas, não é só isso. As aplicações Node.js possuem alto desempenho e baixo consumo de recursos, pois a plataforma funciona com um único thread, e usa um loop de eventos para processar suas funções assíncronas. Por isso é extremamente rápida e eficiente para aplicações de muito thoughput, como RESTful web services.
Criar aplicações servidoras só com o Node.js pode ser trabalhoso e repetitivo. Para evitar isto, e organizar as aplicações, foi criado o framework Express.js, que serve exatamente para criarmos RESTful Web Services, organizando o nosso código-fonte e automatizando muitas tarefas típicas de servidores. Com ele, podemos criar “templates” de páginas HTML e associar o processamento e geração de views às rotas baseadas em URL, tudo automaticamente. Seu papel no Stack MEAN é estruturar o código, criando uma arquitetura SOA para nossa aplicação.
Uma aplicação típica feita com o MEAN tem apenas HTML + Javascript como camada “Cliente”, sendo todo o processamento de regras feito via requests REST. Para apresentar os resultados, muitas vezes temos que mexer com o DOM (Document Object Model) da página, seja manualmente ou usando um pacote como o jQuery. Isso é um trabalho repetitivo e complexo. Para nos ajudar a evitar isso, usamos o Angular.js, que é um framework MVW, para tornar as páginas HTML dinâmicas sem necessidade de modificar manualmente o DOM. Mas ele faz muito mais do que isso, por exemplo, permite injetarmos dependências, criarmos templates etc.
É vantajoso usar o Stack MEAN?
Sem dúvida. Especialmente se você desenvolve aplicações Cliente/Servidor com grande volume de transações, baseadas em acesso a dados.
Aplicações de uso intensivo de CPU, como: Cálculos, Aplicações de tratamento de imagem e outros, podem ter problemas com a arquitetura de Thread único do Node.js, embora exista solução para isso. Aplicações com regras extremamente complexas também podem ser difíceis de fatorar paa funcionar com a linguagem Javascript.
Em resumo, para a maioria das aplicações comerciais, é mais vantajoso usar o Stack MEAN. Eis os principais motivos:
- As ferramentas são baseadas nos padrões da Web aberta, como: HTML 5, Javascript, REST, JSON e outros. Não há protocolos ou técnicas baseadas em padrões fechados, ou com requisitos de licença proprietária. Isto significa que, ao usar MEAN, você tem menos problemas de portabilidade e compatibilidade futura das suas aplicações;
- Usa-se uma só linguagem para implementação de algoritmos: O Javascript, desde o Cliente até ao Banco de Dados. Os bancos NoSQL, como o MongoDB, podem usar Javascript para várias operações. E essa linguagem é aberta e padronizada;
- O desempenho das aplicações é geralmente melhor do que se fossem feitas em outras plataformas, além de possuírem escalabilidade elástica, compatível com ambientes de nuvem. Como o Node.js é uma plataforma C10K, possui um alto desempenho com menor consumo de recursos;
- É mais fácil criar aplicações do que com outras plataformas, possuindo menor “Complexidade acidental” para as mesmas soluções. Além disso, a curva de aprendizado para desenvolver com o Stack MEAN é muito menor do que em Java EE ™, por exemplo;
- Como usam as tecnologias básicas da Web aberta, permitem maior integração dos desenvolvedores e da equipe de Web design.
Node.js: Plataforma Javascript servidora
Node.js é um ambiente de execução de código Javascript, baseado no engine V8, criado pela Google para uso no navegador Chrome. Com o Node.js, podemos executar scripts desacoplados do navegador, ou seja, o código é executado por um processo externo e independente de navegador e até mesmo da Internet.
O site do Node.js é: http://nodejs.org. É uma ferramenta livre, de código aberto, com versões para ambientes Microsoft Windows ™, Linux e Mac OSX TM.
Existem duas características do Node.js que são os seus grandes diferenciais para outras plataformas: Sua API servidora e a sua arquitetura baseada em Eventos. Estas características tornam o Node.js uma plataforma ideal para desenvolvimento de arquitetura SOA, com RESTful Webservices.
O Node.js foi uma das soluções que surgiram para tentar resolver o problema C10K, que visa atender a um grande número de conexões simultâneas, com um consumo mínimo de recursos. Outra solução muito popular é o “nginx” ou “Engine X” (http://nginx.org). Porém, a principal diferença é que o nginx é um Servidor HTTP, e o Node.js é uma plataforma de desenvolvimento Javascript.
Test-drive com o Node.js
Bem, acho que a forma mais fácil de você entender rapidamente o que é o Node.js é fazer um pequeno exercício. O código-fonte é “sessao01/servidor.js”:
// servidor.js - Servidor basico
function inicio() {
console.log('Aguardando conexoes na porta 8080');
}
function mensagem(request,response) {
response.end('OK');
}
// Carrega o modulo http
http = require('http')
// Cria um servidor, passando uma funcao inicial
server = http.createServer(mensagem);
// Faz o servidor aguardar conexoes, passando uma funcao de tratamento
server.listen(8080, inicio);
Eu codifiquei da maneira mais simples possível, de modo que você pudesse entender o código com clareza. Em se tratando de Javascript, isso poderia ter sido escrito de forma mais suscinta, por exemplo:
http = require('http')
http.createServer(function(req,res) {
res.end('OK');
}).listen(8080, function() {
console.log('Aguardando conexoes na porta 8080');
});
Como o Javascript retorna uma referência aos objetos criados, é possível encadear a criação com a invocação do método “listen”. Além disso, podemos ver que passamos duas funções como “callbacks”: uma para responder às mensagens e outra para informar que a conexão está aberta.
Para o Node.js, as duas formas são indiferentes, porém, para nós, é muito mais fácil analisar um código melhor escrito. Vamos lá:
http = require('http')
Neste comando, estamos criando uma variável global chamada “http”, e associando-a ao Objeto retornado pela função “require()”. Desta forma, a variável “http” nos permite usar métodos e propriedades do Objeto retornado.
O Node.js segue a especificação CommonJS que organiza um “ecossistema” Javascript do lado do Servidor, e a função “require()” serve para carregar “Módulos” em Javascript. Você também pode criar módulos, mas não é o objetivo neste momento.
A função “require()” pode carregar módulos da API do Node.js ou módulos próprios. A diferença é o nome.
server = http.createServer(mensagem);
Usamos o método “createServer”, do Objeto “http”, para criar um Objeto capaz de lidar com mensagens HTTP. Como argumento, passamos uma função Javascript que recebe dois objetos:
function mensagem(request,response) {
response.end('OK');
}
Sempre que um REQUEST HTTP for detetado pelo Node.js, esta função será invocada. É um exemplo típico da programação assíncrona do Node.js, ou um “callback”. No nosso caso, usamos o método “end”, que informa ao Servidor que todos os Headers foram enviados e que a mensagem está encerrada, opcionalmente enviando algum dado. Foi o que fizemos. Isso poderia ser reescrito desta forma:
response.write('OK');
response.end();
server.listen(8080, inicio);
Depois de instanciarmos o Servidor e informarmos ao Node.js sobre o nosso “callback” de requests, temos que ativar o Servidor, ou seja, fazê-lo abrir a conexão passiva e aguardar requests. Isto é feito com o método “listen”, que recebe o número da porta TCP e uma função de início., que será invocada quando o socket passivo tiver sido aberto.
Ok, feitas as devidas explicações, vamos executar o código. Abra um terminal e digite o comando:
node servidor
A extensão do arquivo é desnecessária. Você verá a mensagem exibida pelo “callback” de início do Socket passivo:
Temos duas janelas “terminal” abertas. Na primeira, mais ao fundo, subimos o servidor e podemos ver a mensagem exibida pelo “callback” de início. Na segunda, mas na frente, vemos a resposta de um request. São as duas letras “O” e “K” antes do prompt de comando, na segunda linha.
Arquitetura
Antes de você começar a programar, é necessário que entenda um pouco sobre a Arquitetura do Node.js. Para começar, vamos ver essa figura:
Tem duas coisas importantíssimas que você deve aprender ANTES de programar em Node.js: Ele é “single threaded” e usa “non blocking I/O”.
Single Thread
O ambiente de execução do Node.js utiliza um único “Thread” de execução. Quando nossa aplicação Javascript inicia, um loop de eventos é criado para ela, e, após a execução do código imediato na página (assim como qualquer função invocada por ele), o “loop” entra em ação. Isso é o contrário do que os ambientes convencionais, como Servidores HTTP comuns, fazem. Eles abrem vários threads simultâneos e o seu código pode estar sendo executado em paralelo. No Node.js, isso não acontece: seu código JAMAIS será executado em paralelo.
Non blocking I/O
As operações de I/O, incluindo o I/O de rede, são executadas de forma assíncrona, por um “pool” de “threads” separado, logo, elas não bloqueiam a execução do código que as invoca, uma técnica conhecida como “non blocking I/O”. Quando iniciamos alguma operação de I/O, passamos a referência para uma função Javascript, a ser executada quando a operação terminar, ou quando algum Evento importante acontecer. O Node.js repassa isso ao “pool” de “threads” e agenda os Eventos no “loop”, que é processado contínuamente. Quando algum evento acontece, o “callback” agendado é executado.
Essas duas características modificam completamente a maneira como desenvolvemos aplicações... Por exemplo, considere o seguinte trecho de código Java, de uma aplicação Javaserver Faces:
public Usuario logon(String cpf, String senha) {
Usuario usuario = dao.getUsuario(cpf);
Usuario us1 = null;
if (usuario != null && usuario.getSenha().equals(senha)) {
us1 = usuario;
}
return us1;
}
Este método roda em uma classe invocada por um “ManagedBean”, e ele utiliza um Data Access Object, para obger o Objeto “Usuario” do Banco de dados. Eis o método que ele invoca:
public Usuario getUsuario(String cpf) {
return this.getUsuario(cpf, false);
}
public Usuario getUsuario(String cpf, boolean full) {
// Full significa que quer carregar tudo, inclusive mensagens
Usuario usuario = null;
try {
init();
session.beginTransaction();
if (session.contains(usuario)) {
// Para forçar a carga do banco, caso contrário,
// o initialize não funciona.
session.evict(usuario);
}
usuario = (Usuario) session.get(Usuario.class, cpf);
if (full) {
Hibernate.initialize(usuario);
Hibernate.initialize(usuario.getMensagens());
}
session.getTransaction().commit();
logger.debug("Usuário recuperado: " + usuario.getCpf());
}
catch (Exception ex) {
logger.error("Erro ao ler usuário", ex);
}
return usuario;
}
Esses dois trechos de código estão indo no Banco de Dados obter um Usuário, de forma síncrona, ou seja, o “thread” fica esperando (entra em “wait”) enquanto a operação de I/O é executada. Isso não é problema quando temos um Container JavaEE com um monte de “threads” abertos e disponíveis. Daí o grande consumo de recursos que as aplicações JavaEE normalmente apresentam, pois, além do consumo de memória do “thread”, é necessário uma operação de troca de contexto, para que ele entre em “wait” e depois volte a processar.
Se você tentar fazer algo parecido com isso no Node.js, vai travar o “thread” único, fazendo a aplicação parar de responder.
O equivalente a isso, feito em Node.js, teria que ser assim:
- Ao chegar um request, iniciamos uma operação de I/O e agendamos um “callback” de resposta;
- Assim que a operação de I/O for concluída, enviamos a resposta propriamente dita.
Vou mostrar um exemplo disso. É claro que há técnicas aqui que ainda não vimos, mas dá para “abstrair”. Eu criei um banco no “mongoDB” com o nome “meudb”, e com uma coleção de documentos, contendo um único documento JSON:
{ cpf : 12345, nome: 'Fulano' }
É claro que não vimos o MongoDB, mas, como eu já disse, é um banco No-SQL, que lida com objetos JSON.
Então, vou mostrar uma aplicação Node.js que acessa esse banco e retorna os dados (“acessoBanco.js”):
// acessoBanco.js - Servidor basico que acessa um banco de dados
function mensagem(request,response) {
MongoClient.connect("mongodb://localhost:27017/meudb", function(err, db) {
if(!err) {
var usuario = db.collection('usuario');
usuario.findOne({cpf : 12345},
function(err, item) {
if(!err) {
response.end('OK: ' + JSON.stringify(item));
}
});
}
else {
response.end('Erro ao conectar ao banco');
}
});
}
var http = require('http');
var MongoClient = require('mongodb').MongoClient;
server = http.createServer(mensagem);
server.listen(8080, function() {
console.log('Aguardando conexoes na porta 8080');
});
O que eu quero salientar aqui é o impacto que a arquitetura do Node.js tem no desenvolvimento de uma aplicação. Ao contrário do trecho de código Java (mostrado anteriormente), agora, temos que programar nossas operações de I/O de modo assíncrono. Então, node que fizemos o seguinte:
- [var http = require('http');] - Instanciamos o módulo “http”
- [var MongoClient = require('mongodb').MongoClient;] - Instanciamos o módulo “mongodb” e obtivemos uma instância do Objeto “MongoClient”;
- [server = http.createServer(mensagem);] - Instanciamos um servidor HTTP, informando o “callback” de tratamento de requests;
- [server.listen] - Mandamos o servidor abrir a conexão passiva;
Todas essas operações foram executadas de forma assíncrona, ou seja, ao enviarmos o comando “server.listen”, nosso código seguiu em frente, não aguardando se realmente o servidor abriu ou não a conexão.
Quando chega um request HTTP, nosso “callback” (função “mensagem()”) é executado, logo, este será o comando que ele vai executar:
MongoClient.connect("mongodb://localhost:27017/meudb", function(err, db)
Após a execução desse comando, o processamento sai da nossa função “mensagem()”, retornando para o “loop” de eventos. Quando a operação de I/O de conexão com o Banco for concluída, o “callback” será executado, começando pelo comando:
if(!err) {
Se a conexão foi bem-sucedida, então o processamento executará os próximos dois comandos e sairá do “callback”:
var usuario = db.collection('usuario');
usuario.findOne({cpf : 12345}
Note que somente esses dois comandos acima serão executados, e nenhuma resposta será gerada para o Cliente. O método “findOne” criou outro “callback”, a ser executado quando a operação de I/O para ler o registro do Banco de dados for concluída. Quando isso acontecer, o “callback” com estes comandos será executado:
if(!err) {
response.end('OK: ' + JSON.stringify(item));
}
Ou seja, se não ocorreu erro, então vamos concluir a mensagem, enviando o objeto JSON encontrado. O objeto “JSON” nos permite converter um Objeto Javascript em um String, para enviar junto com a mensagem.
O resultado disso pode ser visto na imagem seguinte.
Na janela “terminal” ao fundo, iniciamos nossa aplicação Node.js, e na janela da frente, enviamos um Request HTTP, obtendo a resposta esperada.
Coisa de “doido”, não? É por isso que muitos desenvolvedores Java ODEIAM o Node.js.
Objetos Globais
O Node.js tem alguns objetos e funções globais, pré-definidos. Para ver uma lista completa, podemos ir ao site da documentação (http://nodejs.org/api/globals.html), mas vamos ver alguns deles aqui:
- global : O objeto que reune a coleção de variáveis globais. Se você declarar uma variável SEM usar o “var”, ela virará uma propriedade de “global”;
- process : Possui vários Eventos, propriedades e métodos para controle do Processo no qual sua aplicação Node.js está sendo executada. Por exemplo, para obtermos os argumentos utilizados na linha de comando, podemos acessar “process.argv”. A lista completa está em: http://nodejs.org/api/process.html;
- console : Representa a saída de informações (stdout) ou de erros (stderr). Se usarmos o método “console.log()” mostraremos uma mensagem em “stdout”, e, se quisermos exibir em “stderr”, usamos “console.err()”;
- setTimeout() : É semelhante ao “setTimeout()” usado dentro de um navegador, com os mesmos argumentos. Executa um “callback” após um intervalo de tempo. Pode ser cancelado com “clearTimeout()”;
- setInterval() : É semelhante ao “setInterval()” usando dentro de um navegador. Pode ser cancelado com o “clearInterval()”;
Módulos da API
O Node.js já vem com vários módulos disponíveis para usarmos. É o caso do “http”, que mostrei anteriormente. Estes módulos já estão instalados junto com o Node.js e, para usá-los, invocar a função “require()”, por exemplo:
http = require('http');
Neste comando, eu criei uma variável global chamada “http” e atribuí o objeto do módulo “http” a ela. Daqui em diante, sempre que eu usar esta variável, terei acesso às propriedades e métodos do Objeto. Para usar um módulo é necessário incluir a função “require()”.
A lista com os módulos da API pode ser vista em: http://nodejs.org/api/index.html.
Vamos mostrar brevemente alguns módulos importantes.
File System
Representa o “file system” do Computador, e nos permite acessar arquivos e saber informações sobre eles. Vou mostrar um exemplo simples:
// lista.js - Servidor basico que lista um arquivo
http = require('http');
fs = require('fs');
server = http.createServer(function(req,res) {
var readStream = fs.createReadStream('./lista.js');
readStream.on('open', function () {
readStream.pipe(res);
});
readStream.on('error',function(erro) {
console.err(erro);
res.end(erro);
});
readStream.on('end',function() {
res.end();
});
});
server.listen(8080, function() {
console.log('Aguardando conexoes na porta 8080');
});
A classe “ReadStream” tem um método muito interessante, chamado “pipe()”, que concatena o “ReadStream” com um “WriteStream” para gravação, ou seja, todo o conteúdo é lido e enviado para o “Stream” de gravação, sem intervenção. Note que a execução será feita de forma assíncrona, ou seja, nosso “callback” vai terminar e a operação será feita pelo “pool” de threads de I/O do Node.js.
Na imagem anterior, podemos ver a execução desse exemplo, exibindo o código do próprio script.
Como os métodos do “ReadStream” são assíncronos, como a maioria das coisas do Node.js, temos que criar “callbacks” para os eventos que desejamos interceptar, depois instanciarmos o “Stream”:
readStream.on('open', function () {
readStream.pipe(res);
});
readStream.on('error',function(erro) {
console.err(erro);
res.end(erro);
});
readStream.on('end',function() {
res.end();
});
O evento “open” significa que o “Stream” foi aberto com sucesso, logo, podemos ler o “Stream”, o que fazemos com o método “pipe()”. Este método concatena um “Stream” de entrada em um “Stream” de saída (como o “res”, que é a resposta a ser enviada ao Navegador).
O evento “error” ocorre se houver algum erro de I/O durante a abertura e leitura do “Stream”.
O evento “end” ocorre quando acabar a leitura dos dados do “Stream”. É muito importante fecharmos o “Request”, com o método “end()”. Caso contrário, o Navegador vai ficar rodando eternamente, pois o “Content-length” não foi atingido. Lembre-se sempre de fazer isso!
Se você quiser ler ou gravar arquivos, eu recomendo o uso das classes “Stream” (http://nodejs.org/api/stream.html), ao invés de usar diretamente os métodos do File System.
HTTP
Você pode fazer I/O de rede usando o módulo “net”, que é mais básico (http://nodejs.org/api/net.html). Porém, para efeito desse curso, vou mostrar mais alguns detalhes do “http”.
Já vimos como criar Servidores HTTP:
http = require('http')
http.createServer(function(req,res) {
res.end('OK');
}).listen(8080, function() {
console.log('Aguardando conexoes na porta 8080');
});
Mas podemos fazer um pouco mais... Por exemplo, podemos formatar nossa mensagem de acordo, incluindo Headers e HTML:
// respostaHttp.js - Servidor basico
http = require('http')
http.createServer(function(req,res) {
var saida = '\n' +
'\n' +
'\n' +
'
OK\n' +
'\n' +
'\n';
res.writeHead(200,
{'Content-Length': saida.length,
'Content-Type': 'text/html' });
res.end(saida);
}).listen(8080, function() {
console.log('Aguardando conexoes na porta 8080');
})
Eis o resultado:
E também podemos abrir conexão HTTP Cliente! Com isso, podemos consumir Webservices dentro do nosso código Node.js. Vamos ver um exemplo de aplicação que consulta o Google Maps para saber todos os pontos que ficam em torno de uma coordenada (Latitude e Longitude).
É claro que não é uma aplicação prática, mas serve para demonstrar algumas coisas:
- Como obter os parâmetros de um request;
- Como construir um request para outro Serviço em uma aplicação Node.js;
- Como formatar a saída.
Antes de mais nada, para consumir serviços de localização da Google, é necessário se cadastrar e obter uma “api-key”. Na listagem a seguir, esta chave foi substituída por asteriscos.
http = require('http')
https = require('https');
url = require('url')
http.createServer(function(req,res) {
var url_parts = url.parse(req.url, true);
var query = url_parts.query;
var apiKey='*************';
var queryPath = '/maps/api/place/nearbysearch/json?language=pt&location='
+ query.latitude + ','
+ query.longitude
+ '&radius=10&sensor=false&key='
+ apiKey;
var options = {
hostname: 'maps.googleapis.com',
port: 443,
path: queryPath,
method: 'GET'
};
console.log(queryPath);
var saida = '';
var req = https.request(options, function(respGoogle) {
console.log("status: ", respGoogle.statusCode);
console.log("headers: ", respGoogle.headers);
respGoogle.on('data', function(d) {
saida += d;
});
respGoogle.on('end',function() {
var objetos = eval('(' + saida + ')');
var pagina = '<!DOCTYPE html>';
pagina += "<html><head><meta charset='utf-8'/></head>";
pagina += '<body>';
pagina += 'Em um raio de 10 metros de:';
pagina += '<ul><li>Latitude: ' + query.latitude
+ '</li><li>Longitude: ' + query.longitude
+ '</li></ul>';
pagina += '<table border>';
for(var x=0; x<objetos.results.length; x++) {
pagina += '<tr><th>' + objetos.results[x].name
+ '</th></tr>';
}
pagina += '</table></body></html>';
res.writeHeader(200,
{ 'Content-type' : 'text/html' ,
'Content-length' : Buffer.byteLength(pagina)});
res.write(pagina);
res.end();
});
});
req.end();
req.on('error', function(e) {
console.error(e);
});
}).listen(8080, function() {
console.log('Aguardando conexoes na porta 8080');
});
http://localhost:8080/?latitude=-22.912109&longitude=-43.230156
Para pegar os dois parâmetros, precisamos usar o módulo URL, que é nativo do Node.js:
var url_parts = url.parse(req.url, true);
var query = url_parts.query;
O método “parse” analisa uma URL e, a partir dai, podemos pegar suas partes, como por exemplo a “query”. E teremos cada parâmetro como uma propriedade desse objeto:
var queryPath = '/maps/api/place/nearbysearch/json?language=pt&location='
+ query.latitude + ','
+ query.longitude
+ '&radius=10&sensor=false&key='
+ apiKey;
Montamos o path de nossa URL com a latitude, longitude e outros dados, como por exemplo a “api-key”. Depois, usamos o módulo HTTPS, para construir um request ao Google:
var req = https.request(options, function(respGoogle) {
O “callback” será invocado com a resposta enviada pelo Google. Podemos pegar as propriedades diretamente dela:
console.log("status: ", respGoogle.statusCode);
console.log("headers: ", respGoogle.headers);
Porém, para ler o conteúdo da resposta, precisamos usar o “WriteStream” que foi passado para o nosso “callback”, e ler o conteúdo:
respGoogle.on('data', function(d) {
saida += d;
});
Quando os dados acabam, o evento “end” ocorre no “Stream”, então, podemos pegar o resultado, transformar em objeto novamente e gerar uma página HTML:
respGoogle.on('end',function() {
var objetos = eval('(' + saida + ')');
var pagina = '<!DOCTYPE html>';
pagina += "<html><head><meta charset='utf-8'/></head>";
pagina += '<body>';
pagina += 'Em um raio de 10 metros de:';
pagina += '<ul><li>Latitude: ' + query.latitude
+ '</li><li>Longitude: ' + query.longitude
+ '</li></ul>';
pagina += '<table border>';
for(var x=0; x<objetos.results.length; x++) {
pagina += '<tr><th>' + objetos.results[x].name
+ '</th></tr>';
}
pagina += '</table></body></html>';
res.writeHeader(200,
{ 'Content-type' : 'text/html' ,
'Content-length' : Buffer.byteLength(pagina)});
res.write(pagina);
res.end();
});
});
Na próxima figura, vemos o resultado desse request:
É claro que existem muitos módulos, mas vimos alguns dos mais importantes: HTTP, HTTPS, File System e URL.
Módulos externos e “npm”
O Node.js tem um grande ecossistema, formado por pacotes de software instaláveis. Eles são chamados de “Node Packaged Modules”, e existe um utilitário chamado “npm” que nos permite baixá-los.
Um pacote Node.js é uma pasta que contém um arquivo “package.json”, e o Node mantém um repositório NPM, com vários pacotes desenvolvidos por terceiros. Quando precisamos usar um pacote que não é nativo, ou seja, não faz parte da API do Node.js, precisamos instalá-lo em nosso projeto.
Cada projeto Node.js é um pacote, logo, ele pode conter um arquivo “package.json”, que o descreve e informa quais são as suas dependências (de outros pacotes). Quando temos dependências, podemos instalá-las com o utilitário “npm”:
npm install <nome do pacote>
A dependência será baixada e copiada para uma pasta chamada “node-modules”, dentro da pasta do nosso projeto. Assim, quando usarmos a função “require()” dentro do nosso código, o Node.js procurará o pacote dentro dessa pasta.
Cada dependência que tivermos deverá ser instalada em nosso projeto. Por exemplo, o projeto em que usamos o módulo “mongoDB” não vai funcionar, a não ser que instalemos o “mongoDB” antes:
npm install mongodb
Este comando tem que ser executado na pasta onde criamos o script, pois, desta forma, ele criará uma pasta “mongodb” dentro de “node-modules”, e o módulo estará disponível para uso pelo script.
Quanto temos projetos grandes, isso se torna complexo, além do mais, como vamos gerenciar a versão dos componentes que estamos usando? A melhor prática é termos um gerenciador de dependências, e é exatamente isso que o “npm” faz.
No caso do script “acessoBanco.js”, podemos criar um arquivo “package.json” para ele. Os atributos que precisamos colocar são:
- name : Nome do projeto, sem extensão “js”. Se você pretende criar um pacote público e adicioná-lo ao repositório “npm”, é melhor verificar se o nome já existe. Tem uma url “http://registry.npmjs.org” , que permite verificar isso, por exemplo, tente abrir “http://registry.npmjs.org/mongodb” . Se retornar algo diferente de “not found”, então o nome já foi tomado;
- version : Versão do pacote. Quando rodamos o “npm install” podemos especificar qual versão queremos. Existe um padrão de especificação de versão (“https://www.npmjs.org/doc/misc/semver.html”), que nos permite até determinarmos um intervalo de números de versão. Veja: https://www.npmjs.org/doc/misc/semver.html;
- description : Texto descritivo;
- homepage : A URL do site descritivo do pacote;
- license : A licença de uso do pacote;
- dependencies : As dependências do nosso pacote;
Vamos mostrar um exemplo:
{
"name": "artigomean",
"version": "0.0.1",
"private": true,
"scripts": {
"start": "node app.js"
},
"dependencies": {
"express": "3.5.0",
"jade": "*",
"mongodb": "1.3.23",
"mongoose" : "3.8.8"
}
}
O “npm” nos permite cadastrarmos script para os vários comandos. Neste caso, se digitarmos “npm start”, o comando “node app.js” será executado. Temos algumas dependências específicas, porém, o “jade” está com “*”, significando que qualquer versão serve.
Se tivermos um “package.json” em uma pasta, basta executar o comando “npm install” nela, que as dependências serão baixadas para dentro da subpasta “node-modules”.
Se você quiser saber mais sobre o “npm”: https://www.npmjs.org/
Hora da maromba!
É isso ai! Hora de malhar! Bora fazer uma aplicação Node.js.
Leia com atenção e tente fazer sozinho(a), É claro que, se você “jogar a toalha”, a correção está aqui: “sessao01//resposta”. Se tiver dúvidas contacte-me pelos meios divulgados.
Você vai criar uma aplicação que:
- Recebe uma URL completa, incluindo o nome de um arquivo;
- Verifica se o arquivo existe e, caso não exista, retorne um
status 404 e uma página de erro;
- Caso o arquivo exista, retornar o arquivo.
Porém, você vai criar uma aplicação Node.js, com um arquivo “package.json” completo. E vai usar um módulo externo, o “lith”.
Vamos ver os passos:
- Crie uma pasta para ser o seu pacote de aplicação;
- Nessa pasta, baixe o “lith” e crie um arquivo
“package.json”, depois, execute o comando: “npm
install lith -save”. Você verá que o “npm” incluiu
a dependência no seu arquivo e criou a pasta “node_modules”;
- Altere o arquivo “package.json” para colocar um nome para
sua aplicação e corrija o comando “start” para “node
exercicio1.js”;
- Crie o arquivo “exercicio1.js” usando o arquivo
“lista.js”, do exemplo sobre File System, como template;
Quando chegar um REQUEST, você precisa pegar o “pathname” da URL. Isto pode ser feito como já vimos antes, só que, ao invés de pegar a “query”, pegamos outra variável:
url
= require('url');
lith
= require('lith');
fs
= require('fs');
http.createServer(function(req,res)
{
var
url_parts = url.parse(req.url, true);
var
pathname = __dirname + url_parts.pathname;
A variável global “__dirname” contém o diretório físico onde o script está rodando. Vamos precisar saber o caminho completo para poder baixar o arquivo.
Você deve testar se o arquivo existe ANTES de tentar baixá-lo. Se não existir, então você deve gerar uma resposta com HEADER 404 e um HTML explicativo. Para você não ficar na bronca, aqui está o código que usa o “File System” para testar se um arquivo existe:
fs.exists(pathname, function (exists) {
if (exists) {
Se o arquivo existir, então você deve enviar um HEADER 200, com “Content-type: text/plain”. Depois, abra um “ReadStream” para ele e faça um “pipe()” com a resposta. Você sabe fazer isso, pois já vimos no exemplo “lista.js”, quando falávamos sobre “File System”. Lembre-se que são 3 eventos: “open”, quando “Stream” foi aberto, “error”, em caso de problemas, e “end”, quando terminaram os dados.
Para gerar o HTML, você vai usar o “lith”. Na verdade, não precisava usar nada, é que eu queria forçar você a baixar um módulo externo, e o “lith” parece ser uma boa escolha. Para gerar um HTML com o “lith” você pode usar o método “lith.g()”, passando um array JSON. Por exemplo:
var
saidahtml =
lith.g
([['!DOCTYPE HTML'],['html',[['head',[
['meta',
{charset: 'utf-8'}]]],
['body',[['h1',
'404 Not found']]]]]]);
Isso vai gerar um string HTML, que você pode usar no “res.end()” para enviar ao Navegador. Lembre-se de enviar os HEADERS com Status 200, “Content-type: text/html” e “Content-length” com o tamanho do string HTML gerado.
Eis as imagens de dois casos: um que tentamos um arquivo existente e outro com 404:
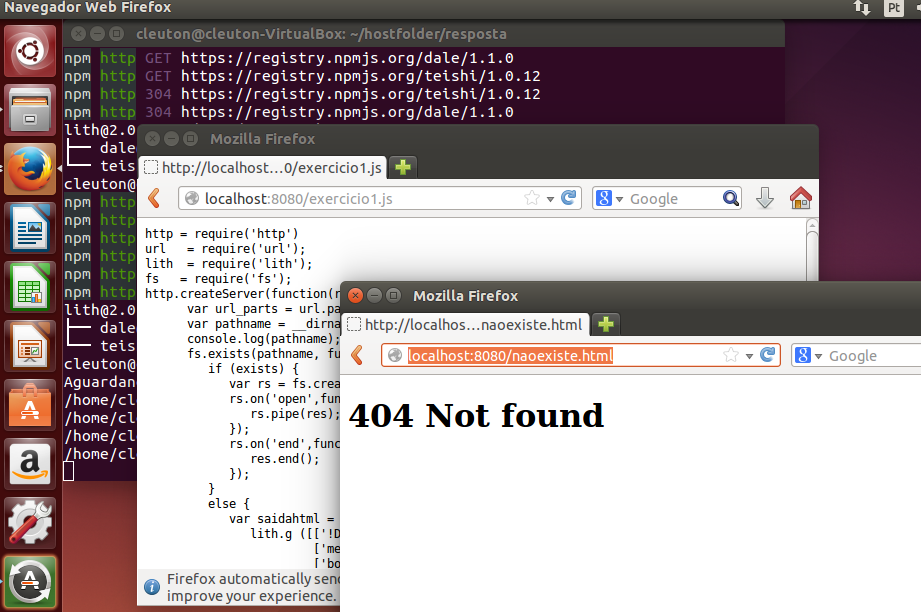
- Exercícios e Vagrantfile para acompanhar o curso;
- Sessão zero: Setup;
- Sessão 1: C10K: Node.js, o Javascript no lado Servidor;
- Sessão 2: Banco de dados No SQL com MongoDB;
- Sessão 3: RESTful Webservices com Express.js;
- Sessão 4: Criação de páginas dinâmicas com Angular.js;
- Sessão 5: Exemplo prático;
Nenhum comentário:
Postar um comentário