
Ainda estamos estupefatos com o desempenho e facilidade acachapantes do Node.js. Realmente, há muito tempo estávamos procurando uma solução simples, que nos livrasse do excesso de complexidade dos frameworks e mecanismos de aplicações corporativas atuais. Assim, embarcamos de cabeça no MEAN stack, certo?
Porém, O Bom Programador adverte: Entrar de cabeça em uma solução, sem compreender como ela funciona, é uma tolice absurda! É exatamente a síndrome do "Golden Hammer", ou pior: "Cargo cult programming".
Por isso, estamos testando, estressando e procurando esclarecer bem alguns pontos "obscuros" do Node.js, para que você saiba exatamente no quê está entrando.
Como funciona o node.js?
Conforme prometido, estou divulgando uma parte do que já estudei até agora sobre o Node.js, que é a base do MEAN stack. Ainda não concluí os estudos, mas resolvi postar logo essa primeira parte, para que você possa ir se acostumado com as idiossincrasias dessa nova plataforma.
Antes de mais nada, gostaria de salientar que continuo acreditando e apoiando o Node.js, assim como o MEAN stack, como alternativas ao Java EE (e a outras soluções corporativas). Os resultados obtidos aqui não devem afetar sua decisão de adoção, mas devem alertar sobre os possíveis problemas e modos de lidar com o Node.js.
Para começar, vamos ver os principais "hilights" que a mídia fala sobre o Node.js:
- Permite criar aplicações de rede rápidas e escaláveis;
- Usa o modelo de I/O não bloqueante e baseado em eventos;
- As aplicações Node.js executam em um único thread;
Uau! Parece mágica, não? Porém, se você estudou pelo menos um pouquinho de Ciência da Computação, ficou com uma "pulga atrás da orelha", não? Afinal de contas, a escalabilidade baseada em threads é o nirvana da programação concorrente, ainda mais com esses servidores de múltiplos núcleos. Como pode uma aplicação single-thread ser escalável?
Se olharmos um código Node.js, veremos que é tudo baseado em callback, certo? Por exemplo, veja esse pequeno extrato de código, retirado do projeto Microblog em Node.js, que publicamos aqui:
// (c) http://www.obomprogramador.com
// REST / JSON WS implementation with Node.js calling Java
var restify = require('restify')
var server = restify.createServer()
var fs = require('fs')
var java = require('java')
// Página da aplicação:
function home(req,res,next) {
fs.createReadStream('./index.html', {autoClose: true}).pipe(res)
}
// Home page:
server.get('/mb',home)
// Start server
server.listen(8080, function() {
console.log('%s listening at %s', server.name, server.url);
});
- Subimos a aplicação usando o node;
- A aplicação cria um "gancho" para o evento de receber um request GET, para a URL "/", passando o Callback que servirá o request;
- A aplicação instancia um servidor HTTP, escutando na porta 8080;
- Chega um request, o loop de eventos do Node.js identifica o Callback a ser invocado (nossa função "home", e a invoca usando seu ÚNICO THREAD;
- A função "home" é invocada, inicia uma operação de I/O para enviar um arquivo "index.html" e retorna;
- O loop de eventos inicia uma operação de I/O assíncrona e retorna;
- Quando a leitura do arquivo terminar, o Callback do módulo "fs" será invocado, e processado dentro do ÚNICO THREAD do Node.js, enviando a resposta de volta;
Olhando distraidamente, temos a impressão que nosso código é todo assíncrono, certo? E há uma confusão entre "assíncrono" e paralelo! São dois conceitos diferentes:
- Assíncrono: O código não aguarda o término de uma tarefa. Ele agenda o código para execução posterior, e retorna imediatamente, deixando um "gancho" para ser executado quando a tarefa terminar;
- Paralelo: O processamento ocorre simultaneamente, sendo executado por várias máquinas, processos ou threads diferentes. O código dispara uma série de tarefas de maneira assíncrona, que são capturadas e podem até serem executadas em paralelo (outro thread em outro núcleo ou mesmo em outra máquina);
É claro que todo código paralelo precisa ser assíncrono, ou seja, precisa saber disparar e recuperar resultados posteriormente, mas nem todo código assíncrono é paralelo. É exatamente o caso do Node.js. Registramos "Callbacks" a serem executados, como no caso da função "home", mas ele usa um único Thread para processar o seu loop de eventos. Logo, é esse mesmo thread que recebe novas conexões e invoca os "Callbacks". O Node.js, ao contrário de outros tipos de servidores (como o Apache), não fica abrindo um Thread por conexão.
Isso tem vantagens, pois evita a troca de contextos ente Threads e diminui o consumo de memória.
Vamos tentar explicar isso graficamente:
Quando uma aplicação Node.js é executada, uma das prineiras tarefas é criar "ganchos" nos vários eventos que podem ocorrer, "pendurando" pequenas funções (closure) chamadas de "callbacks". Depois, geralmente inicia o servidor, que inicia o loop de eventos.
Graças ao mecanismo de Closures do Javascript, podemos criar objetos do tipo "function" e passá-los como argumento. Estes objetos podem ser executados posteriormente, mesmo que a função que os criou já tenha saído de escopo. É o que acontece quando o código abaixo é executado:
// Página da aplicação:
function home(req,res,next) {
fs.createReadStream('./index.html', {autoClose: true}).pipe(res)
}
// Home page:
server.get('/mb',home)
// Start server
server.listen(8080, function() {
console.log('%s listening at %s', server.name, server.url);
});
Note que passamos o objeto "function" "home" como argumento para o método "server.get". Isso criará um "gancho" para quando o "server" receber um HTTP request GET, para a URI "/mb", invocar a função que passamos como "Closure".
Assim são criados vários "Callbacks", para diferentes eventos, que são pendurados em uma lista que é consultada pelo loop de eventos do servidor. Todo o código em amarelo-esverdeado (os da aplicação inicial e os "callbacks") são executados no mesmo Thread do loop de eventos! Isso agiliza a execução e reduz o consumo de memória.
Porém, o Node.js executa todas as operações de I/O, incluindo operações de rede, de modo assíncrono e paralelo, utilizando um "pool" de threads em separado. Vamos repetir e salientar: SOMENTE AS OPERAÇÕES DE I/O E REDE SÃO EXECUTADAS POR UM POOL DE THREADS. O seu código, incluindo o dos "Callbacks", é executado pelo Thread principal, do loop de eventos.
Se nossos "Callbacks" fizerem algum tipo de I/O, ele será disparado pelo loop de eventos para o pool de threads, que executarão o processamento. Se você jogar as cartas direitinho, o "Callback" é liberado imediatamente, liberando o Thread do loop de eventos.
No exemplo anterior, a função "home" cria um "ReadableStream" para ler o arquivo que contém a página "index.html" e usa o método assíncrono "pipe" para escrevê-lo no "WritableStream" de resposta. Isso será executado pelo "pool" de threads, logo, imediatamente após o processamento o seu "Callback" é liberado.
fs.createReadStream('./index.html', {autoClose: true}).pipe(res)
Quando mais usarmos os elementos de I/O assíncrono, mas escalável nossa aplicação será. Se ficarmos fazendo "gracinhas" no código do "Callback", vamos prender o único Thread do loop de eventos, fazendo nosso servidor segurar os requests.
Isso acontece com aplicações de outras arquiteturas, como Java EE ou LAMP (Apache), mas fica "camuflado" por que os servidores usam um monte de Threads para atender aos pedidos. Só que isso tem um custo: Precisamos adicionar mais e mais máquinas.
Essa arquitetura do Node.js é executada pela biblioteca libuv.
Um exemplo ruim
Vamos criar um exemplo bem ruim, usando um código que calcula uma sequência de Fibonacci. Eis o GIST, e co código:São duas práticas ruins:
- Criar código de uso intensivo de CPU (o cálculo da sequência de Fibonacci);
- Escrever a resposta proceduralmente;
Ambas as práticas bloqueiam o thread do loop de eventos, diminuindo ou comprometendo totalmente a escalabilidade da sua aplicação.
Rode o código "node blocker" e abra dois navegadores. No primeiro, digite: "http://localhost:8080" e depois clique no link "blocker", então tente acessar a página inicial ("http://localhost:8080") no segundo navegador. Você verá que ambos ficam bloqueados.
Existem soluções para isso?
Bem, claramente, deveríamos evitar escrever procedimentos dentro do código dos "Callbacks". O ideal é usar pipes ou bancos de dados, nos beneficiando ao máximo do "non-blocking I/O" do Node.js. Por exemplo, o evento da página inicial deveria ser algo assim:fs.createReadStream('./index.html', {autoClose: true}).pipe(res)E podemos usar templates, como o Jade, criando e passando variáveis para códigos de "Callback", que formatariam a página automaticamente. Escrever procedimento manual, como esse:
// Home page:
server.get('/',function(req, res) {
var bodyHtml = '<!DOCTYPE html><html><head><title>'
+ 'Teste Node.js - O Bom Programador</title></head>'
+ '<body>'
+ '<br/>Ok, agora, <a href="/blocker">o blocker</a>';
bodyHtml += '</code></pre></body></html>';
res.writeHead(200, {
'Content-Length': Buffer.byteLength(bodyHtml),
'Content-Type': 'text/html'
});
res.write(bodyHtml);
res.end();
});
É a pior coisa que podemos fazer. Estamos ocupando o Thread do loop de eventos para escrever nossa pagina, que é totalmente estática.
E se eu tiver que calcular algo pesado ou demorado? Por exemplo, uma autorização de cartão de crédito?
Solução 1: Escalar horizontalmente
Podemos subir várias instâncias do nosso servidor Node.js, sejam na mesma máquina ou não, e subir algum tipo de balanceador de carga, para distribuir os requests entre os vários servidores.Solução 2: Dividir o processamento
Podemos também tentar usar algum tipo de assincronia, para delegar as funções demoradas para execução paralela. Existem alternativas para isso, como a biblioteca WebWorker.Demonstração de escalabilidade horizontal
Neste caso, não queremos modificar nosso código, e consideramos que a aplicação demorada (o cálculo da sequência de Fibonacci, não será executado pela maioria dos usuários. Eu sei que pode ser um erro assumir isso, mas nem sempre TODOS os usuários usam TODAS as funções de nossa API, logo, ou então, não podemos dividir a operação entre vários threads.É claro que, nesse tipo e situação (um Fibonacci) não é a melhor solução, mas resolve parte do problema.
Para começar, vamos desenhar uma arquitetura simplória, porém funcional para distribuição de carga:
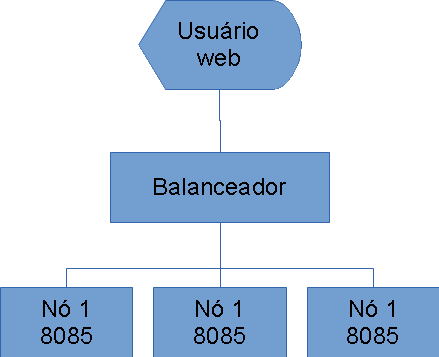
É claro que você pode implementar essa solução com um software dedicado ou mesmo um dispositivo de hardware, mas eu quis criar um balanceador simples, utilizando o pacote "http-proxy". Para instalá-lo rode: "npm install http-proxy" (use "sudo" em caso de sistemas Linux ou Mac).
Eis o Gist do balanceador:
Então, alteramos ligeiramente o blocker.js, e criamos o blockerbal.js, cujas únicas diferenças são: receber a porta via argumento de linha de comando, e retornar o número da porta nas respostas. Eis o Gist.
O http-proxy não é realmente um proxy, no sentido mais literal. Ele não retorna um status 302 (moved) para o Cliente. A transferência é feita apenas no Servidor.
Para testar, subimos o balanceador, e três instâncias do blockerbal.js, cada uma em seu processo. Se preferir, pode usar VMs diferentes e fazer port redirect.
- node balanceador
- node blockerbal 8085
- node blockerbal 8090
- node blockerbal 8095
Ao fazer um request à porta 8080, caímos no balanceador, que encaminha o request para o próximo servidor da lista (round-robin). Eis a resposta:
Eu abri as ferramentas do desenvolvedor do Chrome e mostrei o request e o response. Note que não houve um "redirect".
Bem, abra 3 janelas de navegador e entre em "http://localhost:8080" nas três. Note que cada uma caiu em um servidor diferente. Agora, escolha uma delas, e clique no link. Enquanto estiver rodando, faça refresh nas outras. Você verá que pelo menos uma delas vai continuar respondendo, talvez até duas. Depende de qual servidor o request caiu.
Então, de certa forma, mitigamos o problema. É claro que podemos melhorar isso:
- Adicionar mais servidores;
- Mudar o algoritmo de round-robin para aleatório;
- Fazer "sticky" criando um cookie no response e testando no request, então forçamos todos os requests de um usuário a cairem no mesmo servidor;
- Testar a carga antes de encaminhar o request;
- Separar os servidores por tipo de request, desviando os mais pesados para outros servidores.
Demonstração de programação concorrente
É claro que a demonstração anterior não é a melhor solução, mas pode ser a única, caso você não tenha como mexer no aplicativo. O melhor seria usar um mecanismo que permitisse criar um Thread para atender ao request.
E isso existe para o Node.js! Há uma biblioteca "WebWorker" que permite criar novos Threads e disparar tarefas para eles. Com poucas mudanças, podemos adaptar nosso código para se beneficiar disso. Primeiramente, temos que instalar o módulo: "[sudo] npm install webworker-threads".
Podemos criar instâncias do Worker quando recebemos requests, disparando tarefas que ocorrem em um thread separado do thread principal, impedindo que um processamento pesado bloqueie o servidor. Veja o Gist do novo script "nonblocker.js":
Vamos por partes... A grande mudança é no processamento do request REST GET, com URI "/blocker". Ao receber um request, nosso "Callback", que é executado pelo Thread principal (o mesmo do loop de eventos), faz o seguinte:
- Instancia um Worker;
- Configura o evento de fim de trabalho do Worker (worker.onmessage);
- Posta o número do termo da sequência para o Worker calcular;
- Retorna.
Ao instanciar o Worker, nós fazemos o seguinte:
- Usamos a API global do WebWorker para configurar o que acontecerá quando nosso Worker receber um trabalho. Associamos uma função ao objeto "onmessage";
- Usamos a API global do WebWorker para disparar uma mensagem, baseados no evento recebido;
Depois, fora do código de inicialização do Worker, nós configuramos o que vai acontecer quando o Worker terminar o trabalho ("worker.onmessage"). Recebemos e montamos a página de resposta com o resultado.
Finalmente, postamos uma mensagem para o Worker, passando o número 45. Ela será recebida pelo código do Worker, que a processará. Quando terminar, o evento "worker.onmessage" será invocado.
É interessante notar algumas coisas:
- A instância do navegador que invocou a URI "/blocker", vai ficar bloqueada;
- As outras instâncias não. Podemos fazer vários requests.
Isto acontece porque os requests para a URI "/blocker" estão sendo tratados por um thread separado, independente do loop principal. Isto evita o bloqueio do mesmo.
Como podemos melhorar isso?
Deixar um navegador parado, com o ícone rodando, sem resposta alguma, é receita para um desastre! Os usuários vão reclamar muito! Logo, podemos melhorar isso. Eis algumas maneiras:
- Separar as URIs. Criar uma URI para pedir o cálculo e outra para ver se a resposta já retornou. Ambas enviam e recebem apenas JSON. Podemos colocar uma mensagem "aguarde..." caso o resultado ainda não esteja pronto;
- No servidor, recebemos o request, criamos uma entrada em um banco (MongoDB) e pegamos o "id" para retornar como "cookie". Ao receber um request de status, pegamos o "cookie" e vamos no banco saber se o cálculo já terminou. O Worker atualiza o banco com o resultado, quando ele terminar.
Assim, o usuário receberá alguma coisa e o navegador não ficará "rodando" eternamente. Podemos colocar um refresh automático JSON para testar o status.
Conclusão
Como demonstrei, o Node.js tem características próprias, e pode até ser utilizado para cálculos ou operações demoradas, inclusive de maneira assíncrona. Depende, é claro, de escolhermos a melhor solução.
Eu acredito que sempre devemos optar por usar intensivamente banco de dados (MongoDB), pois operações de I/O são naturalmente paralelas. E devemos abusar de balanceamento de carga e de WebWorkers, sempre que tivermos alguma função REST mais complicada.
Embora nenhuma das duas opções seja necessária, para a maioria das aplicações, uma combinação das duas soluções pode ser a melhor saída para tornar sua aplicação mais responsiva, caso você tenha algumas operações mais demoradas.
E podemos considerar várias outras opções, como gerenciadores de mensagens assíncronas, como o Axon.
O importante é compreender que você não está usando mais Java, e nem um Container, ou que não está mais usando o Apache! Certas coisas, passam a ser da sua responsabilidade.
[set list ouvido durante a confecção esse artigo: Dream Theater, Greatest hits 2008]
Nenhum comentário:
Postar um comentário